Stability Matrix教學
Stability Matrix的使用教學。
Stability Matrix:https://github.com/LykosAI/StabilityMatrix
本地算圖有很多前端,我個人比較貪心,什麼都想試,但又很懶,不想一一修改模型資料夾,所以使用了Stability Matrix。
Stability Matrix可以整合常見的影音生成與訓練前端,模型與輸出圖片資料夾自動共用,也能直接從CivitAI、Hugging Face下載模型與模型的Metadata。
如果和我一樣圖方便,推薦使用Stability Matrix。
但是,Stability Matrix也有缺點,首先是它本身會占用一點效能資源,其次是偶爾前端安裝擴充會出現一些錯誤,但我不確定這是擴充的問題,還是使用整合平台的問題。
不過擴充的問題通常是缺少python套件,把終端的錯誤訊息貼給AI就能得到解決方法。
目前支援的前端:Stable Diffusion WebUI、Stable Diffusion WebUI Forge、ComfyUI、Fooocus、SwarmUI、Cogstudio、FramePack、InvokeAI、SD.Next、Kohya's GUI、One Trainer、FluxGym
安裝前注意事項:
本地算圖需要的VRAM:
建議8GB以上,最低6GB,但速度可能會較慢,不如去使用線上平台。
可以下載模型的平台:
- CivitAI
- Hugging Face
- TensorArt(部分)
- PixAI(部分)
簡單的教學
安裝本體
- 前往下載連結 下載最新版的 StabilityMatrix-win-x64.zip。
- 解壓縮後點擊StabilityMatrix.exe開啟程式,接著等程式跑完,開啟UI介面就好了。
※程式會在所在的資料夾內建立一個Data資料夾,所有的資料都會放在裡面,建議將應用程式放在單獨的資料夾。
安裝前端
- 切換至Packages頁面,點擊下方的Add Package。
- 進入你想安裝的前端頁面。
- 點擊Install。
- 在安裝前端的同時,可以先去下載一個模型,如果你的資料夾內完全沒有模型,首次開啟前端時會自動從Hugging Face下載基礎模型。
- 前端安裝完畢後,點擊Lauch啟動前端即可。
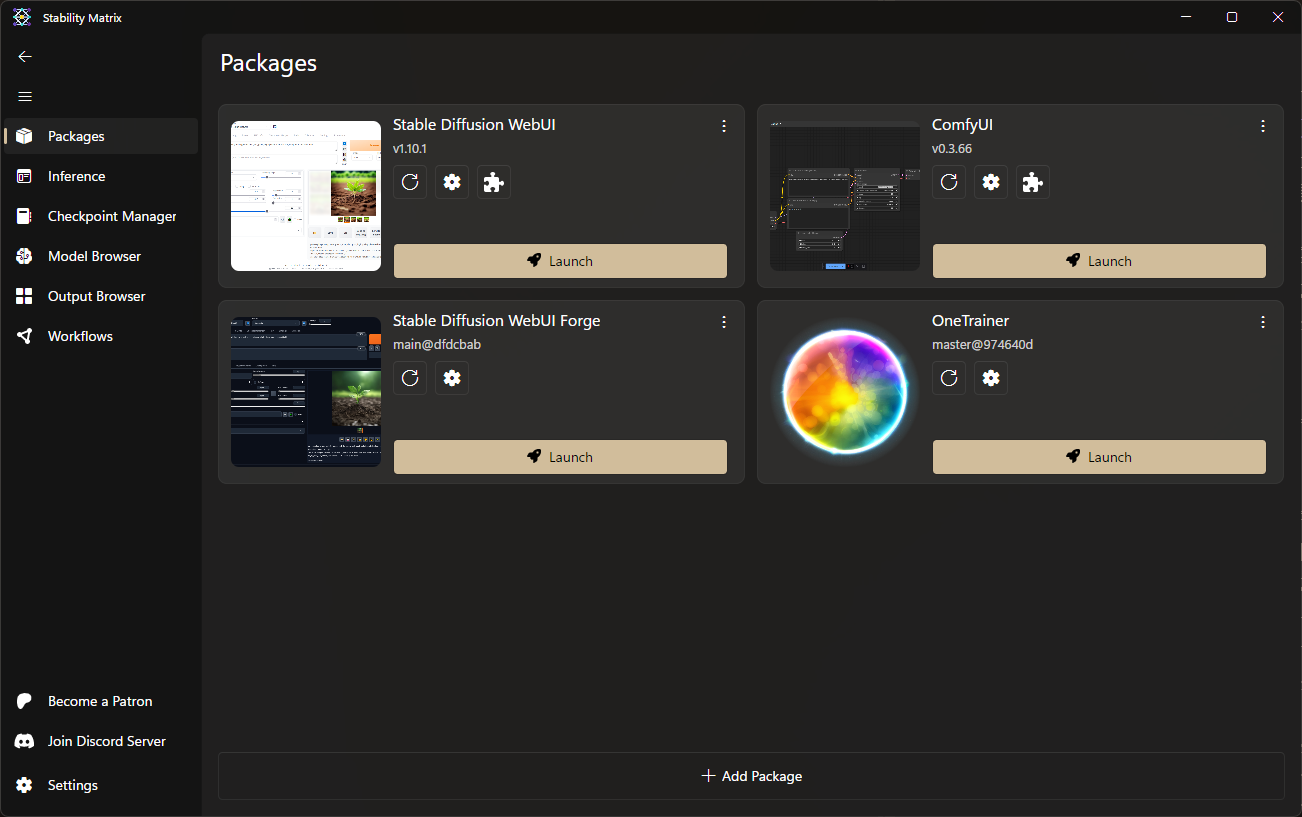
安裝擴充
- 在Packages頁面中,找到你想安裝擴充的前端,點擊拼圖符號。
- 勾選你想安裝的擴充後,點擊Install。
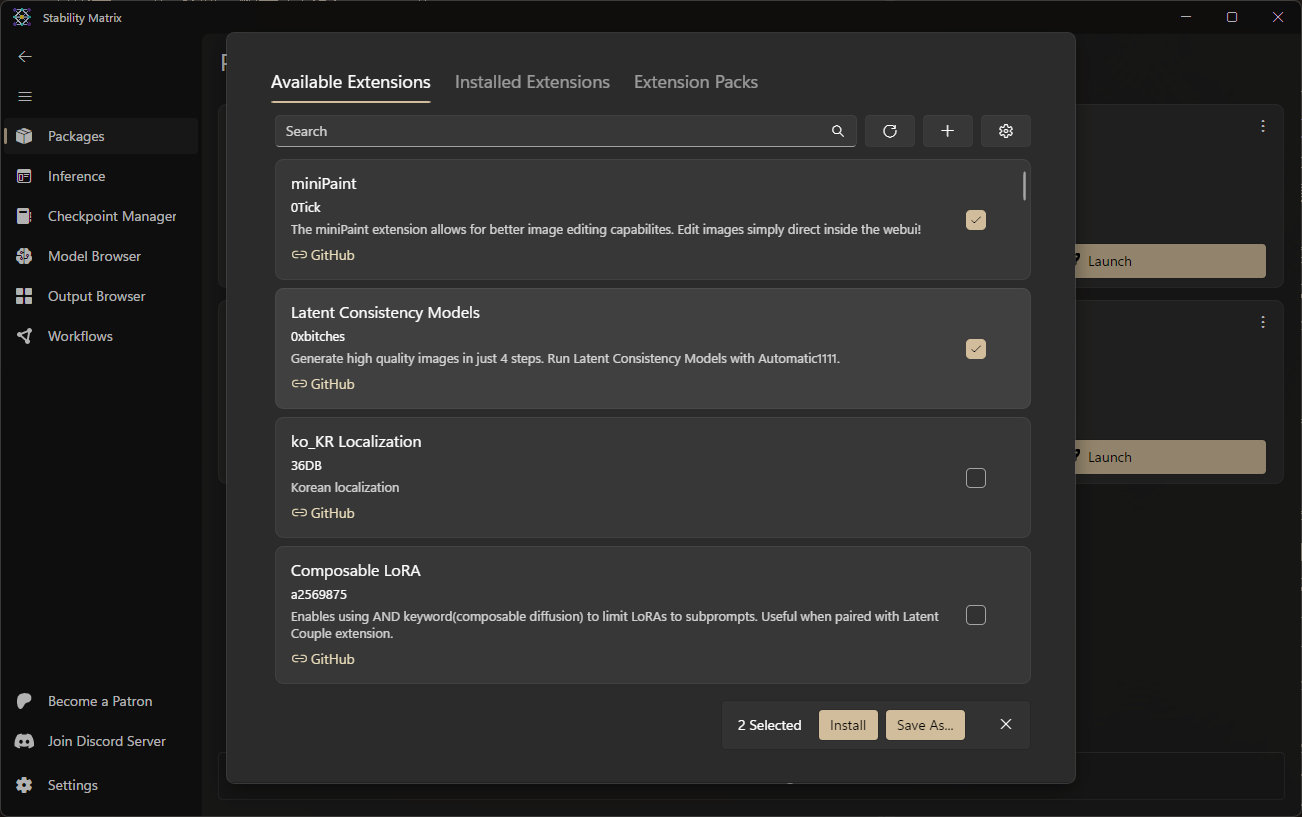
下載模型
- 切換至Model Browser頁面,尋找想要下載的模型。
- 下載方式(以Civit為例):
- 點擊右鍵按Open on Civit後,在模型頁面下載
- 或是點擊左鍵進入模型頁面,點擊裡面的Download下載
- 如果是需要登入會員才能下載的模型,點擊左下角的Setting,進入Accounts項目,在Civit項目點擊Connect,並按照顯示的教學於Civit創建API來連結帳號。
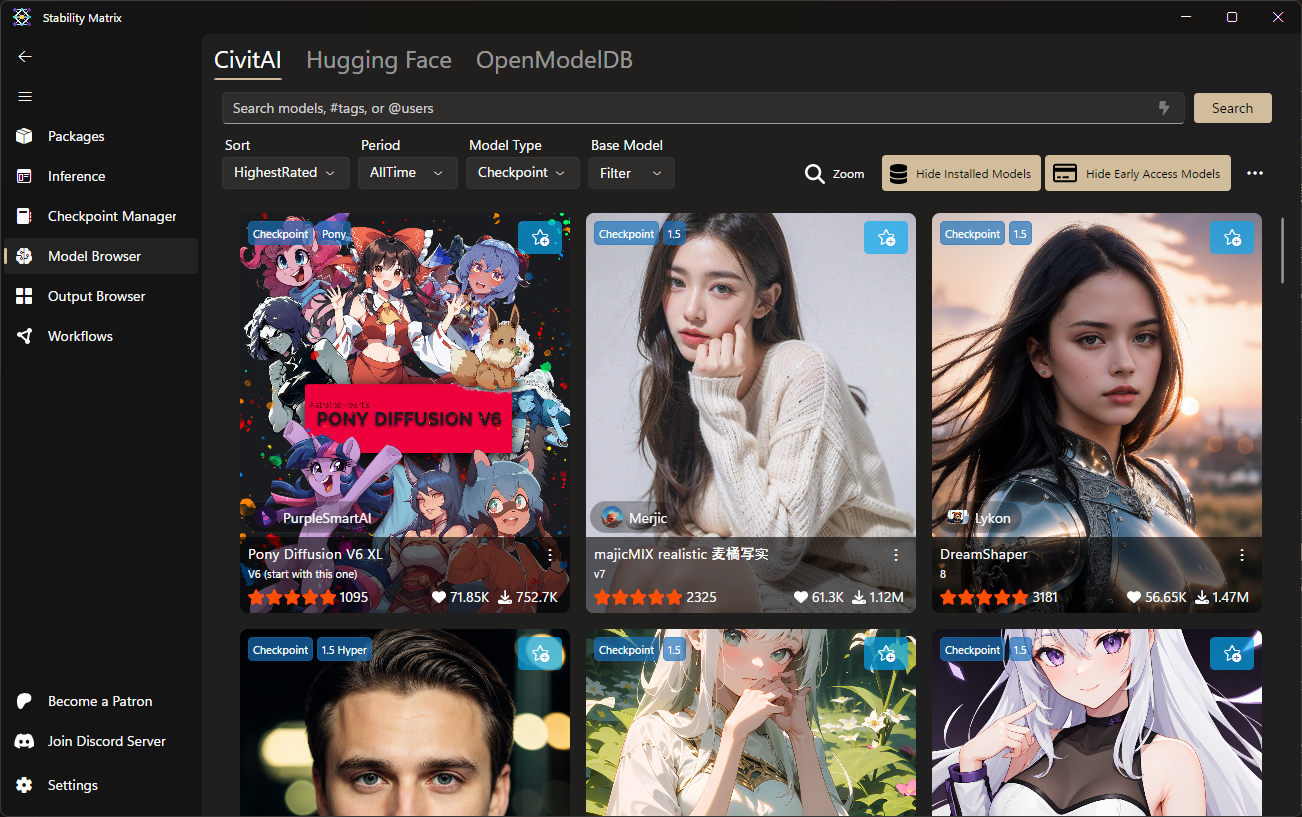
管理模型
- 切換至Checkpoint Manager頁面,可以在這裡管理所有類型的模型。
- 點擊上方的Find Connected Metadata可以自動從Civit下載Metadata,省去自己手動編輯的功夫,不過偶爾還是會有失效或圖片被隱藏的問題,就自己手動修正吧。從其他地方下載的模型也是一樣要手動編輯。
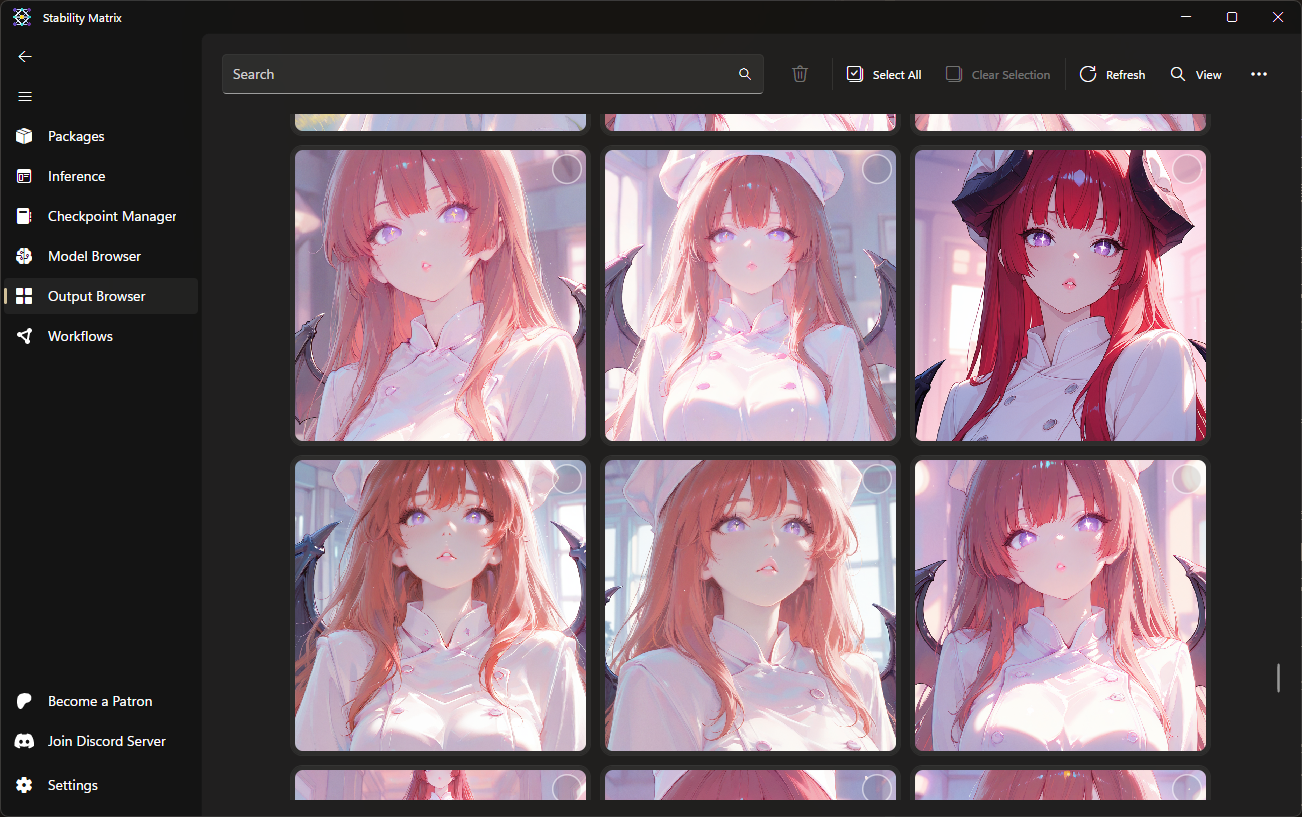
管理圖片
- 切換至Output Browser,可以在這裡查看或刪除所有前端輸出的圖片。
- 可以搜尋提示詞的內容。
- 按右鍵可以將圖片傳送至Inference再製。
※所有輸出圖片不管有沒有在前端點選儲存,都會被存檔下來,記得定時刪除不要的檔案。
※在前端點選儲存的圖片會存到Saved資料夾,可以用右上角的View來開啟資料夾目錄。
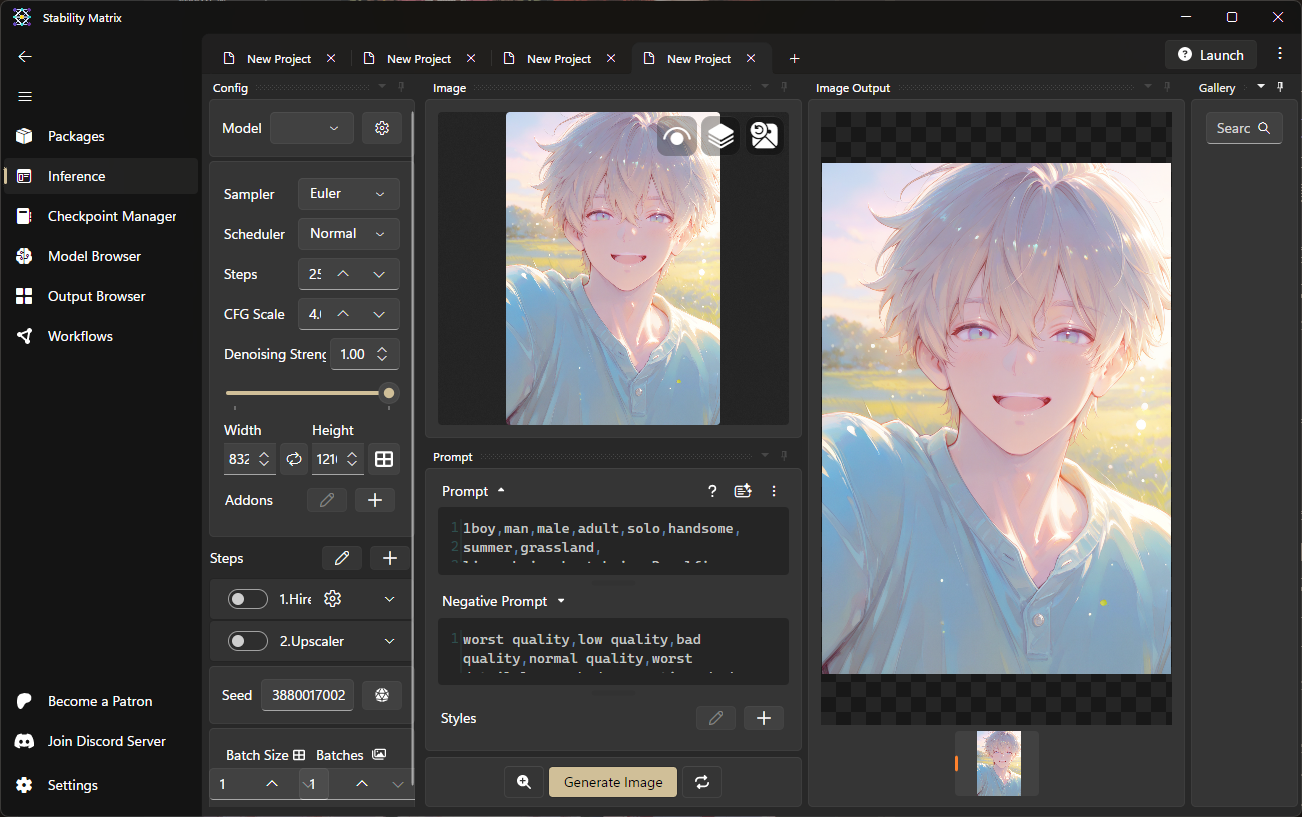
生成或再製圖片
- 切換至Inference頁面,可以在這裡直接使用ComfyUI生成或再製圖片,不過必須先啟動ComfyUI。
- 也可以把圖片拖曳進去查看prompt。
- 基本上就是把ComfyUI做成一個簡單易懂的UI,讓人更容易使用。如果你想用ComfyUI,又對設置工作流感到困難,可以考慮使用這個功能。
介面語言
雖然有熱心網友提供繁體中文介面,但不建議使用。一來基本上是簡轉繁,二來有很多缺失,直接用英文介面還是比較快。
前端簡易教學
這裡簡單教學Forge和ComfyUI,Forge源於WebUI,基本功能差不多,但對新手來說,Forge比較簡單。
Stable Diffusion WebUI Forge
- 在SM點擊Lauch來開啟前端
- 前端網頁開啟後,切換至Extensions頁面
- 將擴充網址貼入URL for extension's git repository後,點擊Install,成功安裝會出現成功訊息。建議安裝以下擴充,其他更多擴充請自行研究:
- prompt-all-in-one:https://github.com/Physton/sd-webui-prompt-all-in-one.git
- adetailer:https://github.com/hinablue/sd-forge-adetailer.git
- Dynamic prompts:https://github.com/adieyal/sd-dynamic-prompts.git
- Tag complete:https://github.com/DominikDoom/a1111-sd-webui-tagcomplete.git
- Ultimate upscale:https://github.com/Coyote-A/ultimate-upscale-for-automatic1111.git
- 安裝完擴充後,關閉前端網頁,在SM點擊Restart來重啟前端
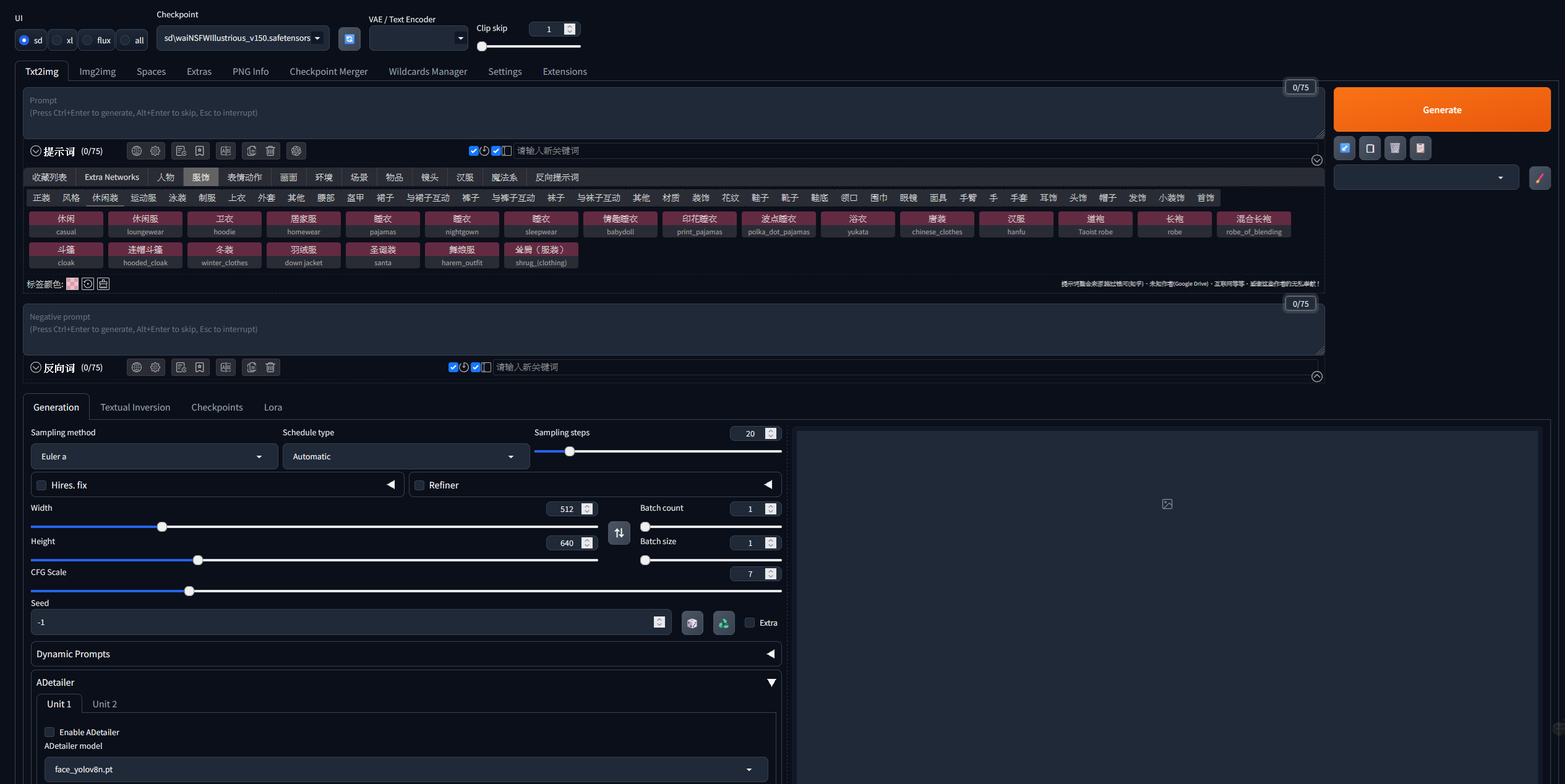
- 前端網頁重啟後,請按照以下步驟,從文字生成圖片:
- 在上方的Checkpoint選擇使用的模型
- 切換至Txt2img頁面
- 在Prompt欄位輸入你的圖片提示詞,本地模型大多無法使用中文算圖,建議使用Danbooru 上的標籤來組成提示詞,如果你想了解更多,可以參考NoobAI-XL用戶手冊中的提示詞指南 。如果想使用LoRA,只需要在下方的Lora頁面點擊想加入的LoRA即可
- 在Negative prompt輸入你不希望圖片出現的元素提示詞
- 在Generation頁面調整參數,最基礎的調整:
- Sampling steps:算圖步數,可參考模型的建議步數,我通常設25
- Width與Height:圖片的尺寸,可參考模型的建議尺寸,過小的尺寸可能會降低圖片品質,不同的尺寸生成的結果也會不同
- Seed:種子,同樣的種子會算出同樣的構圖。在調整提示詞時可以固定種子來確認提示詞造成的影響,在確定提示詞後再改為隨機(-1)
- ADetailer:勾選Enalbe Adetailer,可以修復圖片中的人臉,對品質有明顯的改善,而且幾乎沒有壞處,ADetailer的提示詞空白時會使用主提示詞
- 基礎的內容調整完後,請點擊右方的Generate生成圖片
ComfyUI
ComfyUI有非常非常多進階功能,但對於新手來說不太友善,在WebUI能輕鬆使用的ADetailer需要另外下載擴充並自建節點,較為複雜。
我個人更喜歡使用WebUI,所以只會用簡單的流程。
然後我想了想,嗯,要解釋和截圖的東西好多喔,所以我決定直接貼網路教學(幹
首先是最簡單易懂的PAPAYA電腦教室影片教學:
https://youtube.com/playlist?list=PL7enJ2-v6SPmuHhJEOf0hTplfmq8K_e6D&si=WgDwNEDMycUqMRq2
不想看影片的話,也可以看ComfyUI的官方文件範例:
https://docs.comfy.org/zh-CN/tutorials/basic/text-to-image
這裡有一個簡單的工作流,只有文字生圖加LoRA的功能:
https://drive.google.com/file/d/1QLPddt9SNknfGpAq0oxChHfi_7SCeVCI/view?usp=sharing
應該是某個範例,但我忘記是哪裡下載來的了,我只把最後存檔的圖片名稱做了更動。
如果不更動圖片存檔名稱,新生成的圖片會被存成同一個檔名並覆蓋舊圖片。此工作流生成的圖片會放入yyyy-mm-dd資料夾內,並以圖片生成時間命名。
此工作流沒有加入Upscale、HiresFix、FaceDetailer等功能,生成的圖片品質端看模型、LoRA、提示詞與基礎參數品質,想要使用更多精修功能請自行研究,或使用SM的Inference功能。
如何匯入工作流:直接將檔案拖曳至ComfyUI網頁即可。
Civit上也有許多工作流可以下載使用,在匯入工作流後如果有缺少的擴充,ComfyUI內建的ComfyUI Manager可以幫助你快速找到並安裝缺少的擴充。
TensorAI的系統也是使用ComfyUI,所以該平台上也有許多人製作的工作流可以下載使用,但可能會有TA專用的節點,這部分就要自己修改了。
最後是SM本身也有一個Workflows頁面,可以在這裡瀏覽並下載各種工作流。